主要介绍四种⼤语⾔模型(ChatGPTAPI、⽂⼼⼀⾔、讯⻜星⽕、智谱 GLM)的 API 申请指引和 Python 版本的原⽣ API 调⽤⽅法,读者按照实际情况选择⼀种⾃⼰可以 申请的 API 进⾏阅读学习即可。如果你需要在 LangChain 中使⽤ LLM,可以参照LLM 接 ⼊ LangChain中的调⽤⽅式。
1. 使⽤ ChatGPT
ChatGPT,发布于 2022 年 11 ⽉,是⽬前⽕热出圈的⼤语⾔模型(Large Language Model,LLM)的代表产品。在 2022 年底,也正是 ChatGPT 的惊⼈表现引发了 LLM 的 热潮。时⾄⽬前,由 OpenAI 发布的 GPT-4 仍然是 LLM 性能上限的代表,ChatGPT 也 仍然是⽬前使⽤⼈数最多、使⽤热度最⼤、最具发展潜⼒的 LLM 产品。事实上,在圈外 ⼈看来,ChatGPT 即是 LLM 的代称。
OpenAI 除发布了免费的 Web 端产品外,也提供了多种 ChatGPT API,⽀持开发者通过 Python 或 Request 请求来调⽤ ChatGPT,向⾃⼰的服务中嵌⼊ LLM 的强⼤能⼒。可选 择的主要模型包括 ChatGPT-3.5 和 GPT-4,并且每个模型也存在多个上下⽂版本,例如 ChatGPT-3.5 就有最原始的 4K 上下⽂⻓度的模型,也有 16K 上下⽂⻓度的模型 gptturbo-16k-0613。
1.1 API 申请指引
获取并配置 OpenAI API key
OpenAI API 调⽤服务是付费的,每⼀个开发者都需要⾸先获取并配置 OpenAI API key, 才能在⾃⼰构建的应⽤中访问 ChatGPT。我们将在这部分简述如何获取并配置 OpenAI API key。
在获取 OpenAI API key 之前我们需要在OpenAI 官⽹注册⼀个账号。这⾥假设我们已经 有了 OpenAI 账号,在OpenAI 官⽹登录,登录后如下图所示:

我们选择 API,然后点击左侧边栏的 API keys,如下图所示:
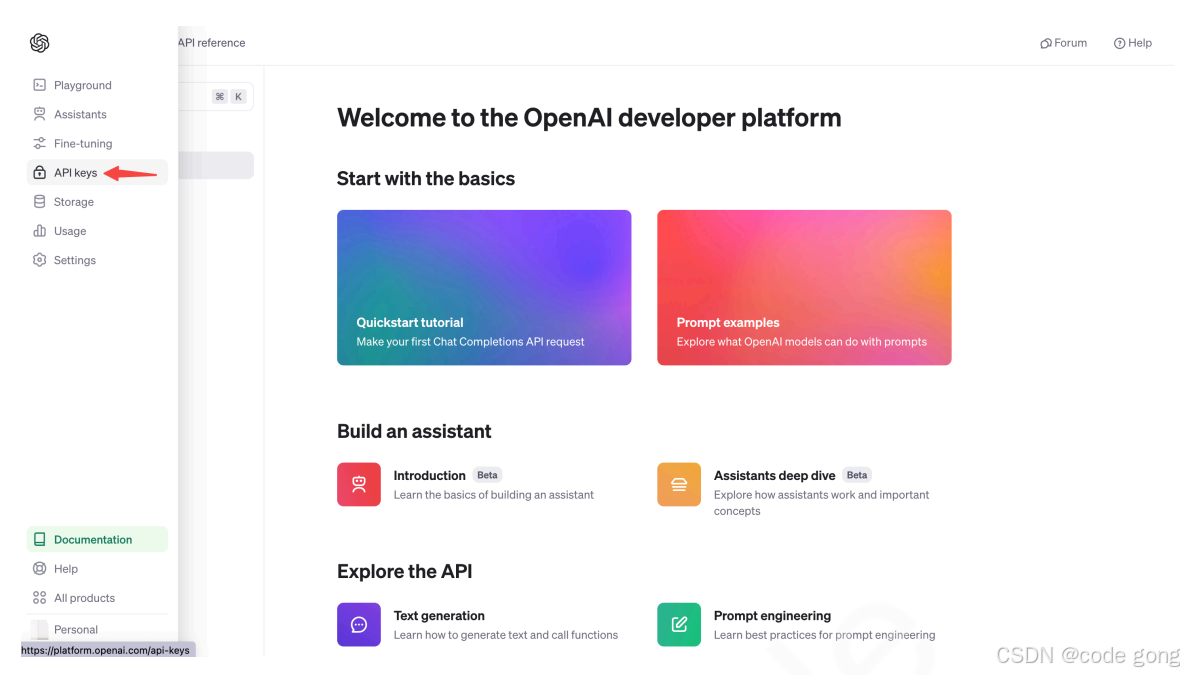
点击 Create new secret key 按钮创建 OpenAI API key ,我们将创建好的 OpenAI API key 复制以此形式 OPENAI_API_KEY="sk-..." 保存到 .env ⽂件中,并将 .env ⽂件保存在项⽬根⽬录下。 下⾯是读取 .env ⽂件的代码:
- import os
- from dotenv import load_dotenv, find_dotenv
- # 读取本地/项⽬的环境变量。
- # find_dotenv() 寻找并定位 .env ⽂件的路径
- # load_dotenv() 读取该 .env ⽂件,并将其中的环境变量加载到当前的运⾏环境中
- # 如果你设置的是全局的环境变量,这⾏代码则没有任何作⽤。
- _ = load_dotenv(find_dotenv())
- # 如果你需要通过代理端⼝访问,还需要做如下配置
- os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
- os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890'
1.2 调⽤ OpenAI API
调⽤ ChatGPT 需要使⽤ ChatCompletion API,该 API 提供了 ChatGPT 系列模型的调 ⽤,包括 ChatGPT-3.5,GPT-4 等。 ChatCompletion API 调⽤⽅法如下:
- from openai import OpenAI
- client = OpenAI(
- # This is the default and can be omitted
- api_key=os.environ.get("OPENAI_API_KEY"),
- )
- # 导⼊所需库
- # 注意,此处我们假设你已根据上⽂配置了 OpenAI API Key,如没有将访问失败
- completion = client.chat.completions.create(
- # 调⽤模型:ChatGPT-3.5
- model="gpt-3.5-turbo",
- # messages 是对话列表
- messages=[
- {"role": "system", "content": "You are a helpful assistant."},
- {"role": "user", "content": "Hello!"}
- ]
- )
调⽤该 API 会返回⼀个 ChatCompletion 对象,其中包括了回答⽂本、创建时间、id 等 属性。我们⼀般需要的是回答⽂本,也就是回答对象中的 content 信息。
completion
ChatCompletion(id='chatcmpl-96AakKPcgCJe6VDXhtnv525jHjE4q', choices= [Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='Hello! How can I assist you today?', role='assistant', function_call=None, tool_calls=None))], created=1711257710, model='gpt-3.5-turbo-0125', object='chat.completion', system_fingerprint='fp_3bc1b5746c', usage=CompletionUsage(completion_tokens=9, prompt_tokens=19, total_tokens=28))
print(completion.choices[0].message.content)
Hello! How can I assist you today?
此处我们详细介绍调⽤ API 常会⽤到的⼏个参数:
- model,即调⽤的模型,⼀般取值包括“gpt-3.5-turbo”(ChatGPT-3.5)、“gpt-3.5-turbo16k-0613”(ChatGPT-3.5 16K 版本)、“gpt-4”(ChatGPT-4)。注意,不同模型的成本是不⼀样 的。
- messages,即我们的 prompt。ChatCompletion 的 messages 需要传⼊⼀个列表,列表中包 括多个不同⻆⾊的 prompt。我们可以选择的⻆⾊⼀般包括 system:即前⽂中提到的 system prompt;user:⽤户输⼊的 prompt;assistant:助⼿,⼀般是模型历史回复,作为提供给模型的 参考内容。
- temperature,温度。即前⽂中提到的 Temperature 系数。
- max_tokens,最⼤ token 数,即模型输出的最⼤ token 数。OpenAI 计算 token 数是合并计 算 Prompt 和 Completion 的总 token 数,要求总 token 数不能超过模型上限(如默认模型 token 上限为 4096)。因此,如果输⼊的 prompt 较⻓,需要设置较⼩的 max_token 值,否则会 报错超出限制⻓度。
OpenAI 提供了充分的⾃定义空间,⽀持我们通过⾃定义 prompt 来提升模型回答效果, 如下是⼀个简单的封装 OpenAI 接⼝的函数,⽀持我们直接传⼊ prompt 并获得模型的输出:
- from openai import OpenAI
- client = OpenAI(
- # This is the default and can be omitted
- api_key=os.environ.get("OPENAI_API_KEY"),
- )
- def gen_gpt_messages(prompt):
- '''
- 构造 GPT 模型请求参数 messages
- 请求参数:
- prompt: 对应的⽤户提示词
- '''
- messages = [{"role": "user", "content": prompt}]
- return messages
- def get_completion(prompt, model="gpt-3.5-turbo", temperature = 0):
- '''
- 获取 GPT 模型调⽤结果
- 请求参数:
- prompt: 对应的提示词
- model: 调⽤的模型,默认为 gpt-3.5-turbo,也可以按需选择 gpt-4 等其他模型
- temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0~2。温度系数
- 越低&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+








 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言